AI 辅助文献检索和文献综述
抛弃手工检索和低效整理,拥抱 AI 驱动的文献综述工作流。
让非技术背景的护理人员也能快速完成文献调研和综述初稿,打破技术壁垒。
⚡ 为什么选择这种方式?
专为临床科研设计,覆盖从选题到综述初稿的全流程。
- ⚡ 极速高效: 从手动检索到 Agent 自主完成文献调研、对比分析和综述撰写,过去需要数天的工作缩短到几分钟。
- 🌐 通用性强: 不依赖特定学术平台,一套 Agent + MCP 逻辑解决 PubMed、Semantic Scholar 等多个数据库的检索与整合。
- ⚖️ 技术平权: 只需会描述需求,无需编程功底,AI 编程工具也能成为你的护理科研助手。
🎯 课前互动
在正式进入内容之前,请先思考两个问题:
- 你用过哪些 AI 工具?(聊天、写邮件、搜文献、写代码……)
- 你觉得 AI 能直接帮你写综述吗?
带着这两个问题的答案,我们开始今天的旅程。
🗺️ 授课内容概览
| 章节 | 主题 | 核心内容 |
|---|---|---|
| 第一章 | 文献检索:科研活动的基石 | 理解文献检索的核心价值,以及选题与检索的螺旋关系 |
| 第二章 | AI 工具的演进逻辑 | 从 LLM 概率模型 → 工具调用 → Agent 主动规划 |
| 第三章 | Agent 与文献综述的结合 | Agent 核心公式拆解,以及开箱即用的入门级工具 |
| 第四章 | 实战演练:Trae + MCP | 快速演示从选题到生成综述初稿的全流程 |
| 第五章 | 总结与展望 | 回顾核心要点,给出实操建议 |
一、文献检索:科研活动的基石
🧭 文献检索是科研的"导航仪"
任何一项有价值的研究,都建立在前人知识积累的基础之上。文献检索的核心价值:
- 避免重复劳动:确保你的研究不是在做别人已经完成的工作
- 把握研究前沿:了解该领域最新进展、热点方向和未解之谜
- 构建理论框架:为你的研究提供坚实的理论支撑和方法学参考
- 发现研究空白:在海量文献中找到尚未被充分探索的领域
【通俗类比】:如果把科研比作航海,文献检索就是你的导航仪。没有导航仪,你可能会在茫茫大海中漫无目的地漂泊;有了导航仪,你才能精准定位,驶向知识的"新大陆"。
文献检索贯穿科研全生命周期
| 科研阶段 | 文献检索的目的 | 检索策略 |
|---|---|---|
| 选题阶段 | 发现研究空白,确定研究方向 | 广泛检索,了解领域全貌 |
| 论证阶段 | 验证选题的科学性和可行性 | 精准检索,聚焦核心问题 |
| 设计阶段 | 确定研究方法、工具和量表 | 方法学检索,参考成熟方案 |
| 写作阶段 | 支撑论点,对比讨论结果 | 针对性检索,补充关键文献 |
| 投稿阶段 | 选择合适期刊,了解发表趋势 | 期刊文献计量分析 |
科研选题与文献检索的螺旋关系
科研选题和文献检索之间存在螺旋上升的互动关系。
从临床经验到研究概念
【护理案例】:假设你是一名儿童外科护士。你发现——低龄儿童的疼痛评估非常困难。因为低龄儿童语言表达能力尚未发育完全,无法通过自我报告来描述疼痛,往往只能通过哭闹、面部表情变化、肢体抗拒等行为来间接表达,评估完全依赖护士的主观判断。这种主观性导致不同护士的评估结果可能存在较大差异,进而影响镇痛方案的制定。
经过提炼,形成研究概念:
“无法自我报告的儿童疼痛客观评估方法研究”
第一轮文献检索:探索现有方法
有了概念之后,进行第一次文献检索,了解目前学界已经有哪些解决方案。
检索策略可能包括:
- 关键词:
低龄儿童疼痛评估、客观指标、生理参数、行为量表 - 检索数据库:PubMed、CINAHL、CNKI
检索结果可能会告诉你,目前针对无法自我报告的儿童,已有以下评估方法:
- 行为观察量表:如 FLACC 量表、NIPS(新生儿婴儿疼痛量表),由护士观察儿童的面部表情、肢体活动、哭闹、可安慰性等指标进行评分。这是目前临床应用最广泛的方法,但高度依赖评估者的主观判断
- 生理参数监测:如心率变异性(HRV)分析、NIPE 指数监测仪,通过自主神经系统反应间接评估疼痛,但易受其他因素(如发热、药物)干扰
- 新兴技术:近红外光谱(NIRS)监测大脑反应、计算机视觉自动识别疼痛表情等前沿方法正在发展中
第一轮检索的核心目的:了解"别人已经做了什么",找到研究空白(Research Gap)。
确定初步选题
通过第一轮检索,你可能会发现:
- 传统行为观察量表临床应用成熟,但仍依赖评估者的主观判断,不同评估者之间可能存在较大差异
- 心率变异性(HRV)等生理参数监测在婴儿群体中已有应用,但在儿童中的验证研究较少
- 计算机视觉自动识别疼痛表情在成人实验室研究中已有初步成果,但在儿童群体中的应用文献极少,仍处于快速发展阶段
基于这些发现,初步确定选题方向:
“基于面部表情分析的儿童疼痛客观评估方法研究”
第二轮文献检索:论证选题的科学性与可行性
| 论证维度 | 核心问题 | 检索内容 |
|---|---|---|
| 科学性 | 这个选题有理论依据吗? | 面部表情与疼痛反应的关联研究 |
| 可行性 | 技术/工具是否可用? | 开源面部识别框架、疼痛表情数据集 |
| 人群验证 | 目标人群是否适用? | 低龄儿童面部表情特征与成人的差异 |
| 方法学 | 测量方法是否完备? | 深度学习模型训练流程、准确率评估指标 |
第二轮检索的核心目的:验证"这个选题能不能做、值不值得做"。
【延伸思考】:在论证选题可行性的过程中,你可能会发现表中的每一个问题本身都可以是一个独立的研究方向。例如:
- “儿童面部表情特征与成人的差异” → 可以单独做一篇儿童疼痛表情特征分析的论文
- “不同护士对同一疼痛表情的评估一致性” → 可以写一篇疼痛评估者间信度研究
- “不同光线/角度对面部表情识别准确率的影响” → 可以写成技术条件优化的研究
科研选题不一定要做一个大而全的系统,把一个具体问题研究透彻,同样有价值。
文献检索驱动选题的完整闭环
【关键洞察】:文献检索不是一次性的任务,而是一个迭代过程。每一次检索都会加深你对研究领域的理解,每一次理解都会反过来优化你的检索策略。
二、AI 工具的演进逻辑:从"孤立的大脑"到"全能助手"
既然文献检索如此重要,为什么过去做起来总是那么费劲?传统检索方式面临着几个痛点:
- 海量信息筛选困难:PubMed 上检索一个关键词,可能返回上千篇文献,逐篇阅读耗时耗力
- 跨库检索效率低:需要在 PubMed、CINAHL、CNKI 等多个平台反复切换
- 对比分析工作量大:提取多篇文献的核心发现、方法、局限性,手动整理非常繁琐
- 最新文献追踪难:领域进展日新月异,人工跟踪最新发表的文献几乎不可能
AI 的出现,正是为了解决这些痛点。 但在这之前,我们需要先理解 AI 到底进化到了什么程度。
在这里,我们所指的"AI"是狭义的 LLM(大语言模型,Large Language Model)。
LLM 的更新速度极快,应用产品几乎以月为单位迭代。有个段子说:“在 AI 时代,最好的应对办法就是不学习,因为你辛苦学到的东西可能一个月后就过时了。”
但是,不能因为 AI 产品迭代快就放弃学习 AI,反而要积极拥抱 AI,了解 AI 的底层逻辑,你才能判断哪些知识值得深入学习、哪些只是昙花一现的表面应用。目前来说,首先要学习的是 LLM 的基础知识(LLM 原理、工具调用、Agent 架构)。无论产品形态如何变化,底层逻辑不会变。
第一层:LLM 的本质 —— 只有算力的"孤立大脑"
LLM 的底层逻辑是一个概率模型——它通过前面的文字,去预测下一个最可能出现的文字。
【通俗举例】:就像手机输入法里的"联想词"。当你输入"白日依山",AI 会计算出下一个字是"尽"的概率最高。当这种计算规模达到千亿级别,并经过海量人类知识的训练,它就"涌现"出了类似人类的理解和推理能力。
【局限与痛点】:这个大脑非常聪明,但它是"孤立"的。知识停留在被训练的那一天,无法获取最新文献,也没有眼睛和手脚。为了解决这个问题,我们进入了第二层。
第二层:工具调用(Tool Calling)—— 给大脑装上"手脚"
开发者给 LLM 制定了一套"接头暗号",让它能够指挥外部程序,这就是工具调用。
【通俗举例】:你问 AI"帮我查一下昨天刚发表的 Nature 封面文章",单纯的大脑不知道。但我们给它配了一部"对讲机"。AI 收到问题后输出暗号:“呼叫网页搜索工具,检索昨日 Nature 封面”。外部工具执行检索后,把内容传回给 AI,AI 再把冰冷的数据组织成流畅的语言告诉你。
【关于 MCP 和 Skills】:你可能听过这些概念。MCP本质上是工具调用的标准化接口,让 AI 能够以更统一的方式调用外部服务。Skills 则是将常用工作流封装为可复用的技能包。它们都是工具调用生态的延伸,让工具调用更规范、更易用。
【局限与痛点】:有了工具,AI 终于能获取新知识了。但它仍像"算盘"——你拨一下,它动一下。要写一篇完整的文献综述,你依然需要一步步下达指令。能不能让它自己规划?于是我们来到了第三层。
第三层:从"被动执行"到"主动规划"
人类使用 AI 的方式经历了一条清晰的进阶之路:
- 提示词工程 (Prompt Engineering):靠"念咒",指令写得越精细,AI 干得越好。
核心组件:角色设定 (Role) → 背景信息 (Context) → 具体任务 (Task) → 输出格式 (Format)
- 上下文工程 / RAG (Context Engineering):主动把 PDF 论文"喂"给 AI,让它基于资料回答。这叫"开卷考试"。
- Agent (智能体):这是质的飞跃!AI 不再是被动工具,变成了拥有"规划和执行能力"的数字员工。你只需说一句:“帮我综述一下低龄儿童疼痛评估的最新进展。“它会自主决定:先搜文献 → 再读摘要 → 最后写综述。
三、Agent(智能体)与文献综述的结合
Agent 核心公式拆解
从"大脑"到"手脚"再到"主动规划”,最终汇聚成了当前 AI 时代的核心概念——Agent(智能体)。
Agent = LLM(大脑) + 规划与记忆(笔记本) + 工具箱(手脚/Tool Calling)
| 组件 | 类比 | 在 Trae 中的实现 |
|---|---|---|
| LLM(大脑) | 思考和推理能力 | 在 Trae 设置中选择模型(如 GPT、Claude、Qwen 等) |
| 规划与记忆(笔记本) | 记录任务进度和上下文 | 对话历史 + 项目文件夹 + 规则文件(.trae/rules) |
| 工具箱(手脚/Tool Calling) | 连接外部世界的能力 | MCP Server、Skills 配置(学术搜索、文件读写、浏览器自动化等) |
规划与记忆:Agent 的"笔记本”
Agent 的"笔记本"负责记录任务进度和上下文信息。在 Trae 中,这主要通过以下方式实现:
- 对话历史:保持对话的连贯性,让 Agent 记住之前的讨论内容
- 项目上下文:将文献、笔记、大纲等文件放在同一目录下,Agent 会自动读取这些文件作为上下文
- 规则文件(.trae/rules):定义项目级别的规则,指导 Agent 的行为模式
工具箱的扩展:MCP 和 Skills
MCP 本质上是工具调用(Tool Calling)的标准化接口。它让 AI 能够以更统一的方式调用外部服务。而 Skills 则是将常用的工作流封装为可复用的技能包。它们都是 Tool Calling 生态的延伸,而非独立的新层级。
【具体案例】:以医学文献检索为例,开发者做了一个
paper-search-mcp。你可以把它想象成一个专门插在 AI 上的"PubMed 数据库 U盘"。有了它,AI 就能直接通过这个标准化接口,连接到学术数据库精准检索论文。
从被动到主动:Agent 自主规划流程
当你对 Agent 说:"帮我写一篇关于’低龄儿童疼痛评估’的文献综述,并保存到桌面上。"
入门首选:开箱即用的 AI 综述工具
在进入 Trae + MCP 这类需要技术配置的"高阶方案"之前,并非所有 AI 辅助文献综述工具都需要编程基础。
| 工具类型 | 技术门槛 | 配置时间 | 适合场景 |
|---|---|---|---|
| AMiner / Elicit / Gemini Deep Research | 低(网页操作) | 5分钟 | 快速了解领域、初步文献调研 |
| Trae + MCP | 高(需懂 JSON、API、Python) | 1-2小时 | 深度定制、长期科研工作流 |
先学简单工具,再学复杂工具——这是让零基础研究者建立信心和直观体验的正确顺序。
AMiner:学术文献智能探索
AMiner(https://aminer.cn)是由清华大学唐杰教授团队开发的学术社交网络与分析平台,近年来集成了大模型能力,可以直接生成文献综述。
- AI 综述生成:输入研究主题,自动检索相关论文并生成结构化综述
- 学者画像:帮你快速了解某领域的重要研究者
- 文献关联分析:可视化展示文献之间的引用关系
适用场景:当你对某个护理主题只有模糊方向时,AMiner 可以帮你快速建立领域全景图。
Elicit:专注文献综述的 AI 工具
Elicit(https://elicit.com)是专门为研究者设计的 AI 辅助文献综述工具。
- 智能文献检索:不只是关键词匹配,而是理解你的研究问题
- 文献摘要提取:自动提取每篇文献的研究目的、方法、结论、局限性
- 对比分析:将多篇文献并排对比,找出共识和分歧
- 研究问题生成:帮助你从文献中发现研究空白
适用场景:当你已经有了一个明确的研究问题,需要快速筛选和理解相关文献时。
Gemini Deep Research:Google 的深度研究助手
Gemini Deep Research 是 Google 在 Gemini 中集成的深度研究功能。开启 Deep Research 模式后,它会自主规划检索策略、浏览多个网页、整合信息,生成一份结构化的研究报告。
- 自主规划检索:不是简单匹配关键词,而是理解问题后制定检索策略
- 多源整合:自动访问多个信息源,包括学术数据库、新闻、技术文档
- 结构化报告:生成带有章节框架的研究报告
适用场景:当你需要对一个主题进行快速但全面的初步调研时,10-15 分钟即可完成过去需要几天才能做完的工作。
其他值得关注的工具
| 工具 | 特点 | 适用场景 |
|---|---|---|
| Consensus | 专门检索和理解学术论文,支持提取论文结论 | 快速确认某个观点是否有研究支撑 |
| Semantic Scholar | AI 学术搜索,结合了文献检索和论文理解 | 深度学术调研,引用网络分析 |
| Perplexity for Research | 实时网络检索 + 引用追踪 | 追踪最新研究进展 |
| Scholarcy | 自动提取论文摘要、关键发现、局限性和未来方向 | 快速筛选大量文献 |
如何选择入门工具
建议的入门路径:
选择建议:
- 时间紧迫、快速摸底:先用 Gemini Deep Research,10 分钟出结果
- 需要英文文献筛选:Elicit 是最专注的工具
- 想了解领域全貌和核心作者:AMiner 的可视化分析更强
- 护理领域中文文献:目前仍需结合 CNKI、万方,配合人工筛选
【重要提醒】:以上所有工具生成的内容都需要人工核实。AI 会存在幻觉,可能将不存在的文献、不准确的结论整合进输出中。护士研究者在使用这些工具时,必须以自己的专业判断作为最终把关。
四、实战演练:使用 AI 编程工具自动化完成文献综述
本节将以 Trae 为例,快速演示如何配置并使用 AI Agent 完成一篇完整的文献综述任务。
⚡ 本节是"抛砖引玉"性质的快速演示。完整的工作流需要课后自行练习。
核心组件配置
在开始之前,我们需要为 Trae 配置以下核心组件。这些组件对应着 Agent 公式中的各个要素:
大脑(LLM 模型)
大脑的质量直接决定任务执行的质量。目前国内外 LLM 的排名日新月异,大家可以前往 LMSYS Chatbot Arena 排行榜 查看最新排名。
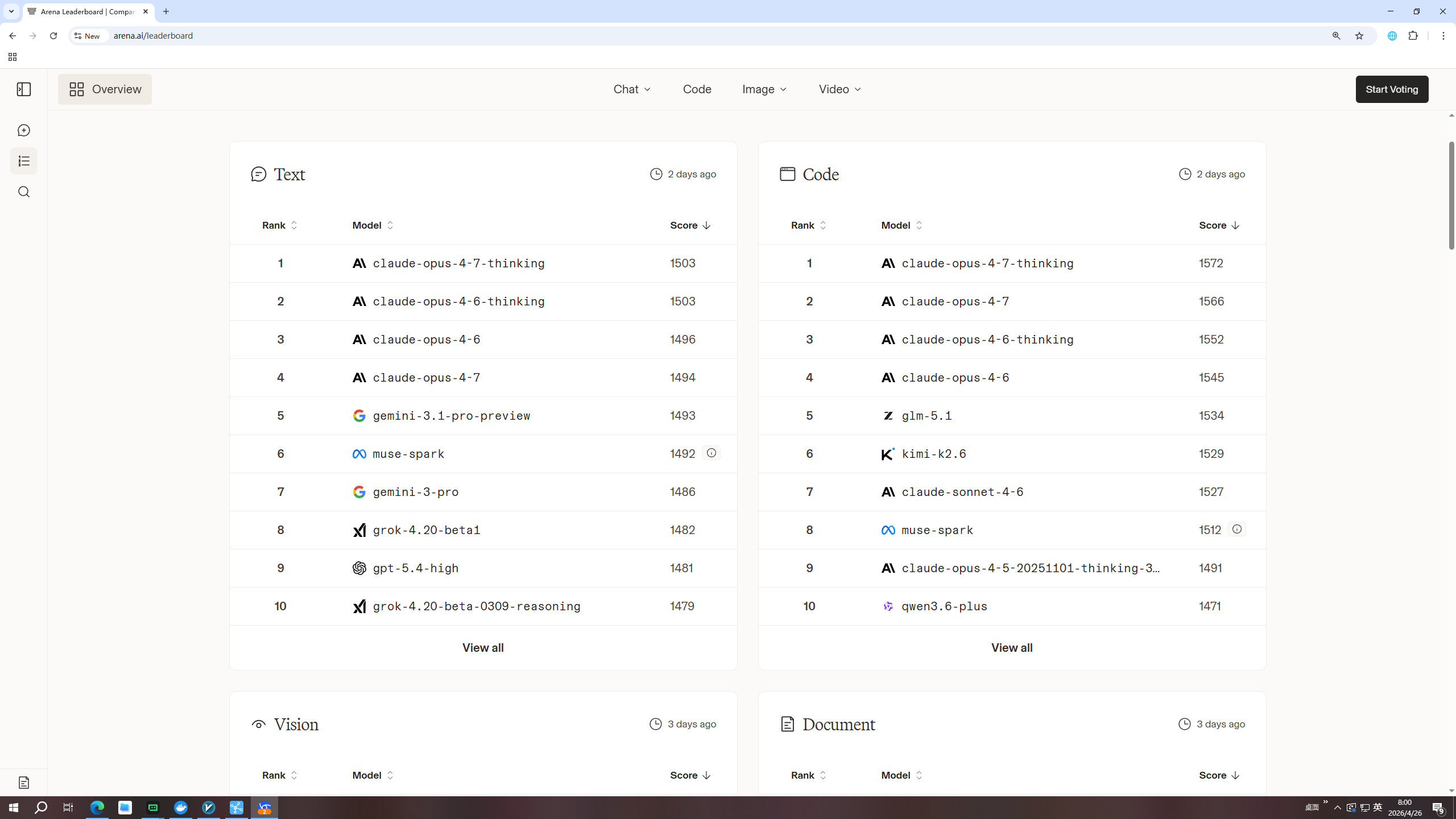
从性价比角度,推荐的模型如下:
| 类别 | 推荐模型 | 特点 |
|---|---|---|
| 国内模型 | GLM-5.1 | 中文理解能力强,适合中文文献处理 |
| Qwen-3.6-Plus | 综合性能优异,推理能力强 | |
| DeepSeek-V4 | 最新模型,代码和推理能力突出 | |
| 国外模型 | GPT-5.4 | 综合能力最强,工具调用稳定 |
| Gemini-3.1-Pro | 长文本处理能力强,适合大量文献分析 | |
| Claude Opus 4.7 | 推理和写作能力出色 |
【选择建议】:如果你的任务以中文文献为主,优先选择国内模型;如果需要检索英文数据库(如 PubMed),国外模型在英文理解上略有优势。
工具箱配置
工具箱是 Agent 的"手脚",决定了它能做什么。对于文献综述任务,Trae 自带的工具调用能力包括:
- 网页搜索:用于检索互联网上的公开信息、新闻、博客等
- 文件读写:用于读取本地 PDF 文献、保存综述结果
- 浏览器自动化:用于访问学术数据库网站、下载文献摘要
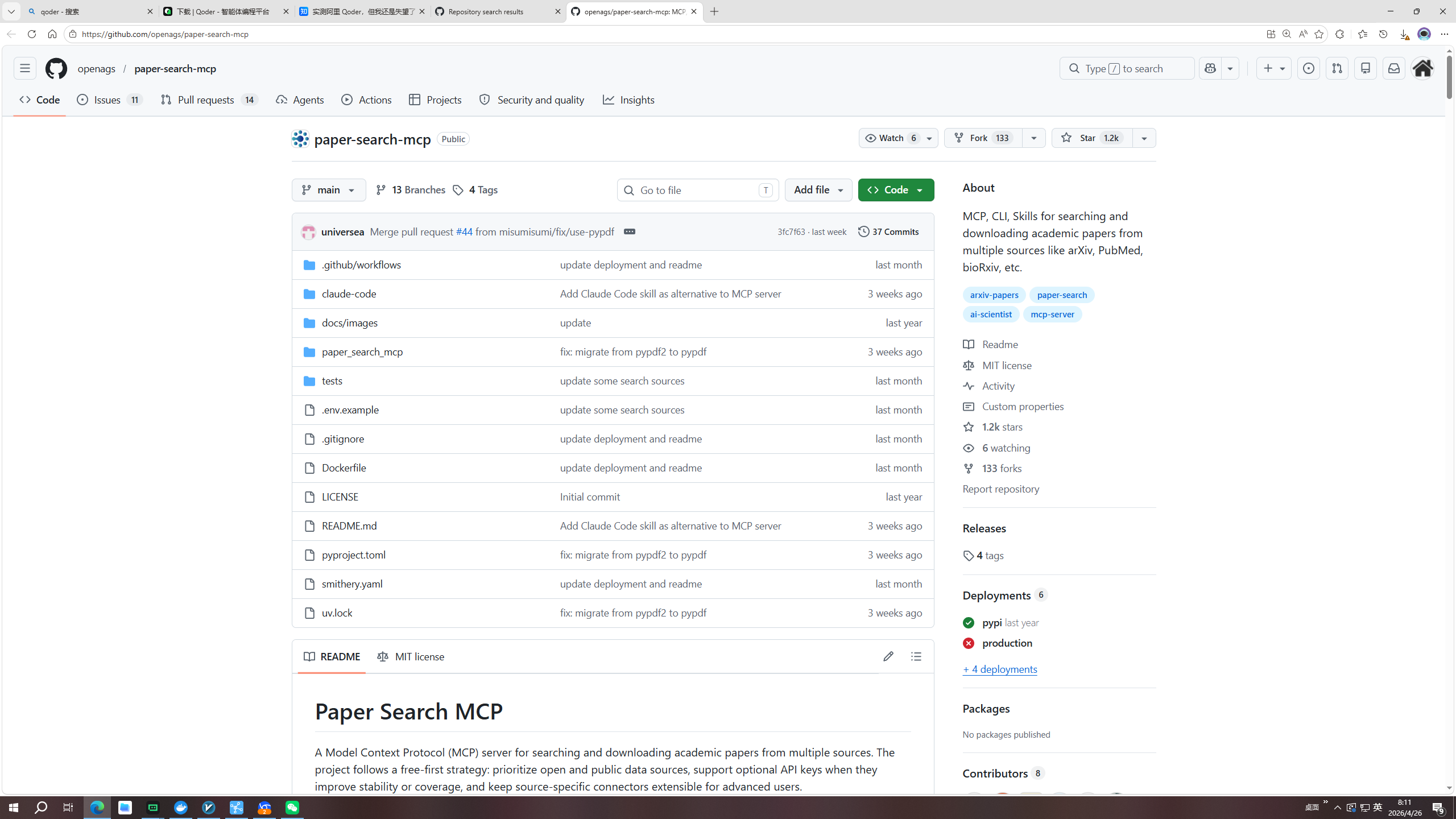
如需检索学术数据库(如 PubMed、Semantic Scholar),则需要额外配置专门的 MCP 工具(如 paper-search-mcp)。更进一步,还可以配置网页自动化工具(如 playwright-cli),让 AI 能够模拟人类操作浏览器,完成更复杂的网页交互任务。
规划与记忆(上下文管理)
Agent 的"笔记本"负责记录任务进度和上下文信息。在 Trae 中,这主要通过以下方式实现:
- 对话历史:保持对话的连贯性,让 Agent 记住之前的讨论内容
- 项目上下文:将项目相关的文献、笔记、大纲等文件放在同一目录下,Agent 会自动读取这些文件作为上下文
- 规则文件(.trae/rules):可以定义项目级别的规则,指导 Agent 的行为模式
- 智能体角色:Trae 支持创建专属的智能体角色,将角色设定(如"资深护理学研究者")和常用工作流封装为一个可复用的智能体,直接省去每次输入提示词的麻烦
创建专属智能体角色
Trae 允许你创建专属的智能体角色,将角色设定和常用工作流封装为一个可复用的智能体。
操作方法:
在 Trae 的设置中找到"智能体"选项,点击创建新智能体。你可以直接用自然语言描述你期望的角色,Trae 会自动生成相应的系统提示词和配置。
护理研究智能体示例:
你可以创建一个专门用于护理科研的智能体角色,例如:
- 角色名称:护理科研助手
- 角色设定:你是一位资深的护理学研究者,擅长文献检索、整理、综述撰写等科研全流程工作。你熟悉 PubMed、CINAHL、CNKI 等数据库检索,理解护理学常见研究设计( RCT、量表编制、现象学研究等),能够根据用户的研究主题提供精准的文献检索和综述建议。
- 预设工作流:当用户提出文献综述任务时,自动执行"确定研究主题 → 文献检索 → 提取关键信息 → 生成综述大纲 → 逐章撰写"的标准流程。
这样,每次新建对话时只需选择这个智能体角色,就能省去重复输入角色设定的麻烦。
【跨界洞察】:你可能会疑惑——一个编程工具怎么能用来做护理科研?这要从底层逻辑说起。编程工具的本质是"写代码",而代码是命令计算机工作的底层语言,也就是说,编程工具理论上可以操作计算机的一切。而科研活动(文献检索、数据分析、论文撰写)本质上都是在计算机上完成的。当 AI 能够帮助你操作计算机,这些工作对它来说就不在话下了。护理研究者不需要学习编程,只需要用自然语言描述你的需求,AI 就能帮你操控电脑完成科研任务。这才是 AI 编程工具能够参与所有科研活动的底层逻辑。
快速任务演示
任务目标:完成一篇关于"无法自我报告疼痛的低龄儿童疼痛评估工具与技术"的文献综述
步骤 1:创建项目文件夹
在本地创建一个文件夹,例如 c:\Users\YnLo\Desktop\non-verbal-pediatric-pain-assessment\
步骤 2:在 Trae 中打开项目
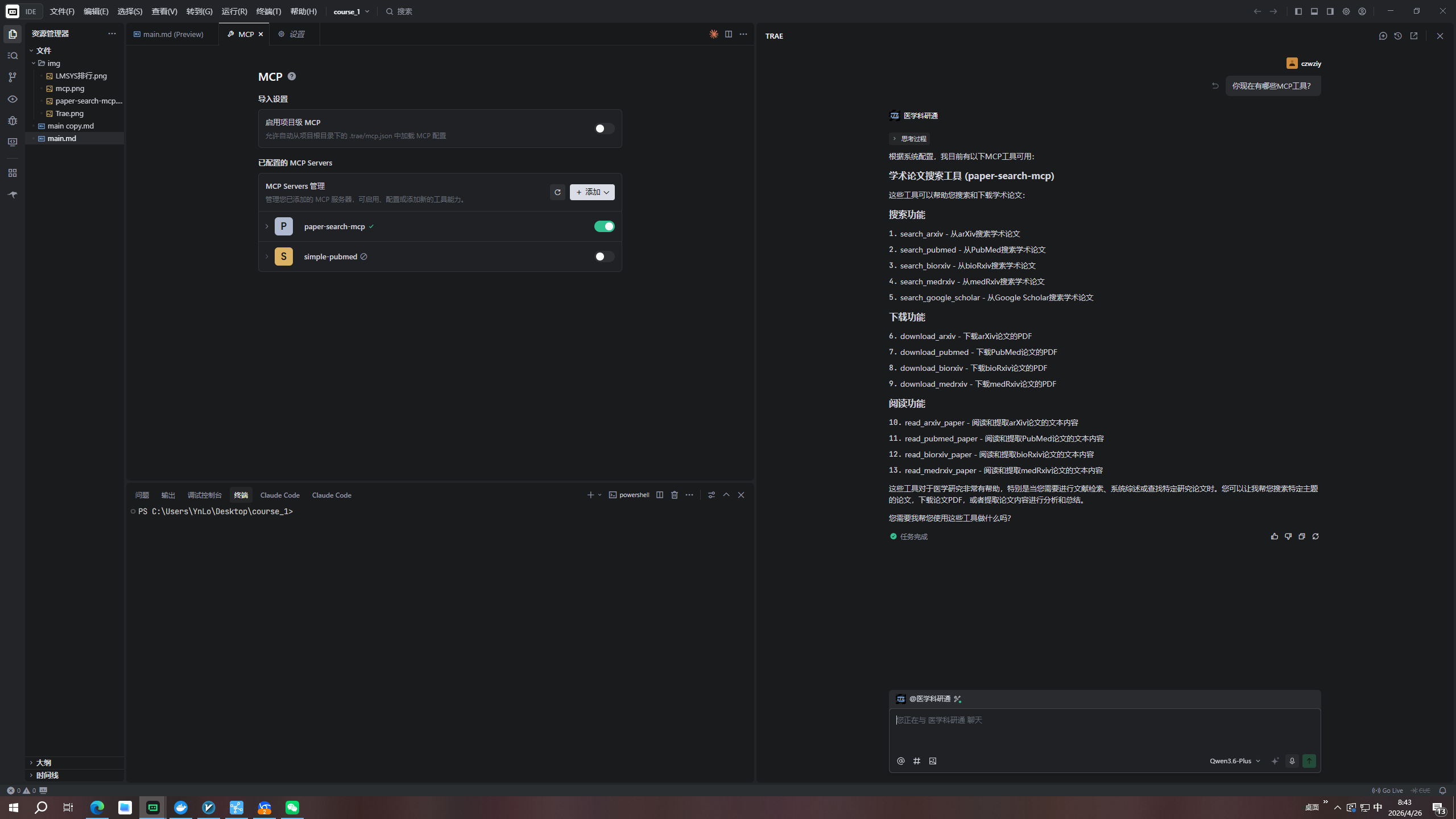
打开 Trae,选择"打开文件夹",选择刚才创建的项目文件夹。
步骤 3:配置 MCP 工具
在 Trae 的设置中,添加以下学术搜索 MCP 配置:
{
"mcpServers": {
"paper-search-mcp": {
"command": "python",
"args": [
"-m",
"paper_search_mcp.server"
],
"env": {
"PAPER_SEARCH_MCP_UNPAYWALL_EMAIL": "czwziy@ynlo.top",
"PAPER_SEARCH_MCP_CORE_API_KEY": "",
"PAPER_SEARCH_MCP_SEMANTIC_SCHOLAR_API_KEY": "",
"PAPER_SEARCH_MCP_ZENODO_ACCESS_TOKEN": "",
"PAPER_SEARCH_MCP_GOOGLE_SCHOLAR_PROXY_URL": "",
"PAPER_SEARCH_MCP_IEEE_API_KEY": "",
"PAPER_SEARCH_MCP_ACM_API_KEY": ""
}
}
}
}
步骤 4:输入任务指令
在 Trae 的对话框中输入以下提示词:
【占位符说明】:以下提示词中的
pediatric-pain-assessment是论文核心词的英文缩写,请根据你的实际研究主题替换。例如:如果你的主题是"糖尿病足护理",可以替换为diabetic-foot-care。
# 角色设定
你是一位资深的护理学研究者,擅长撰写系统综述和Meta分析,对无法自我报告的儿童疼痛评估领域有深入的专业知识。
# 任务背景
我正在撰写一篇关于"无法自我报告的儿童疼痛评估"的文献综述,目标读者是临床护理研究者和护理专业研究生。综述需要做到字字有出处,所有观点和论点都必须有文献支撑。
# 执行流程
请严格按照以下流程执行,严禁一次性生成全文:
Step 1:开始之前,先和我进行头脑风暴以确定研究题目,过程中你可以使用MCP工具检索文献。
Step 2:根据研究题目,继续初步检索文献,并生成综述撰写大纲,保存为 `pediatric-pain-assessment/spec.md`。停止并和用户头脑风暴确定大纲,过程中可以继续检索文献。
Step 3:根据大纲制作详细的检索和撰写计划/步骤,保存为 `pediatric-pain-assessment/plan.md`。
Step 4:根据计划(plan.md),按照"确定章节主题 → 检索相关文献 → 撰写该章节"的节奏,逐章完成
每完成一章后,简要汇报该章节的文献检索结果和核心观点,再继续下一章
# 检索要求
- 使用文献检索工具(如MCP)进行文献检索
- 检索近5年的相关文献
- 筛选高质量研究:优先选择系统综述、随机对照试验、技术验证研究
- 对每篇拟引用的文献,提取以下信息备用:
* 摘要
* 核心发现
* 论文标识符,如doi/pmid
# 输出格式要求
- 使用 Markdown 格式
- 标题层级清晰(## 一级标题,### 二级标题,#### 三级标题)
- 关键信息使用表格或列表呈现
- 语言风格:学术、严谨、客观
# 绝对要求(必须遵守)
1. 严禁编造或使用不存在的文献,所有引用必须真实可查
2. 非常识性的观点和论点必须有文献引证
3. 引证格式:使用 `[@doi:xxx]`、`[@pmid:xxx]`、`[@arxiv:xxx]` 或 `[@title:xxx]` 格式,紧跟在被引证的句子后面
4. 同一观点/句子的引证文献以1篇为宜,最多不超过3篇
5. 如果某章节的文献检索结果不足,请如实说明,不要强行拼凑内容,可以使用"【待引证】"作为占位符
6. 文末**不需要**放置参考文献的列表
# 最终输出
将完整的综述保存为 `pediatric-pain-assessment/draft.md` 文件。
步骤 5:等待 Agent 执行
Agent 会按照提示词中定义的流程自主执行:
- 头脑风暴阶段:与你讨论并确定研究题目,期间会调用文献检索工具辅助决策
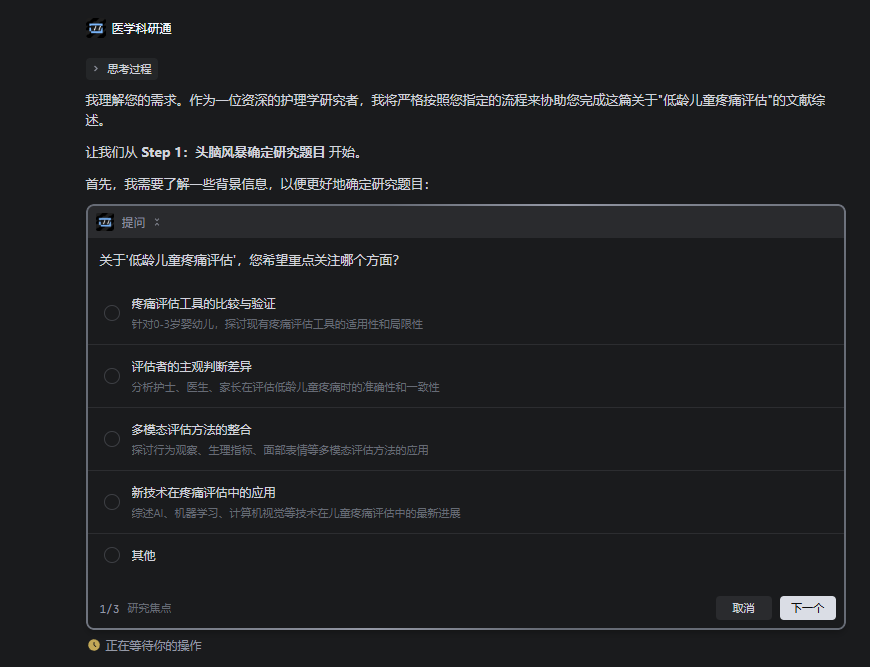
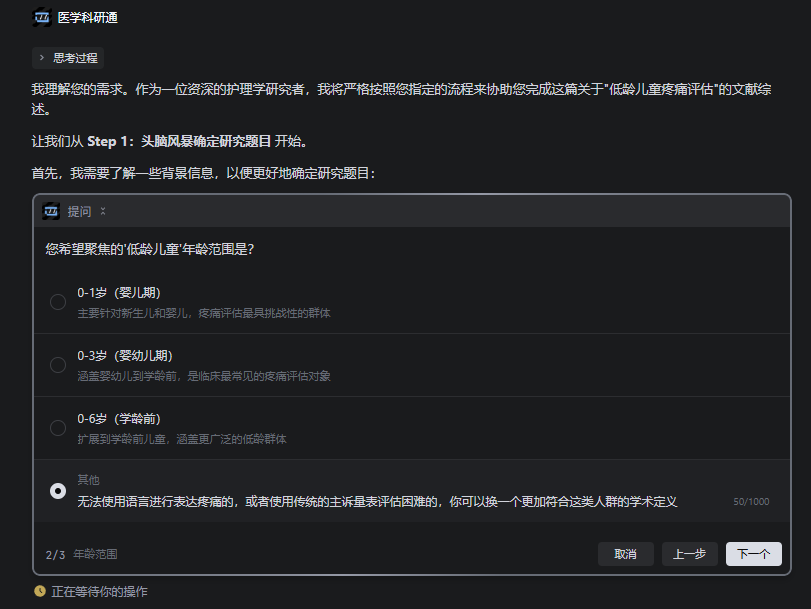
- 大纲生成阶段:根据确定的题目,初步检索文献后生成综述大纲,保存为
spec.md,等待你确认
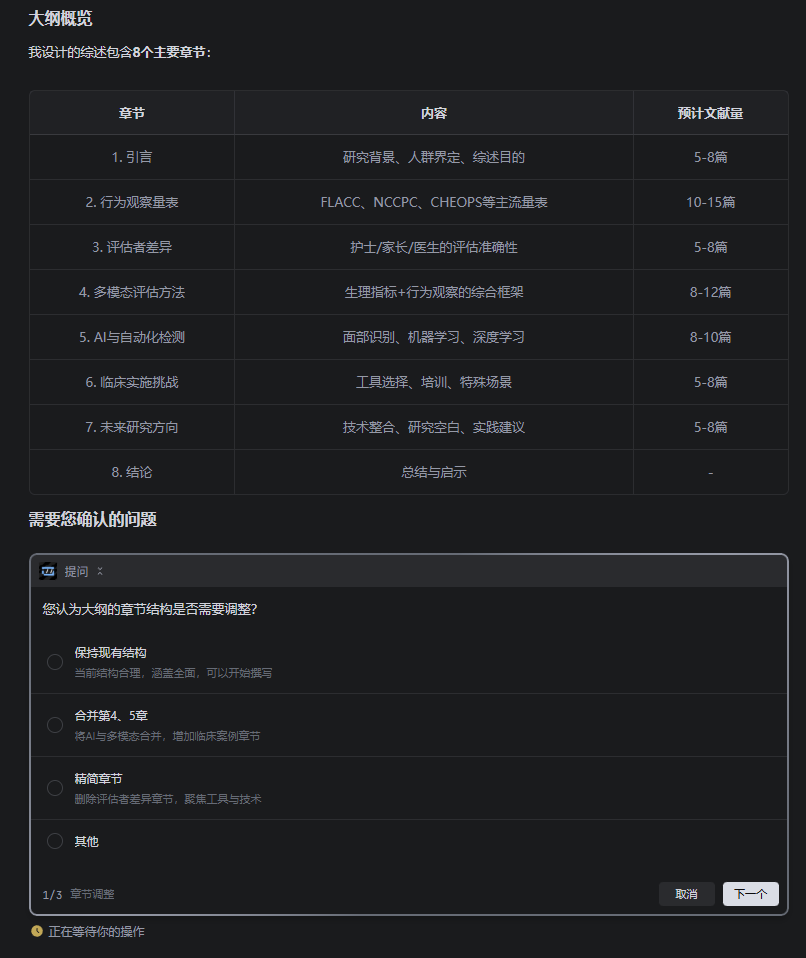
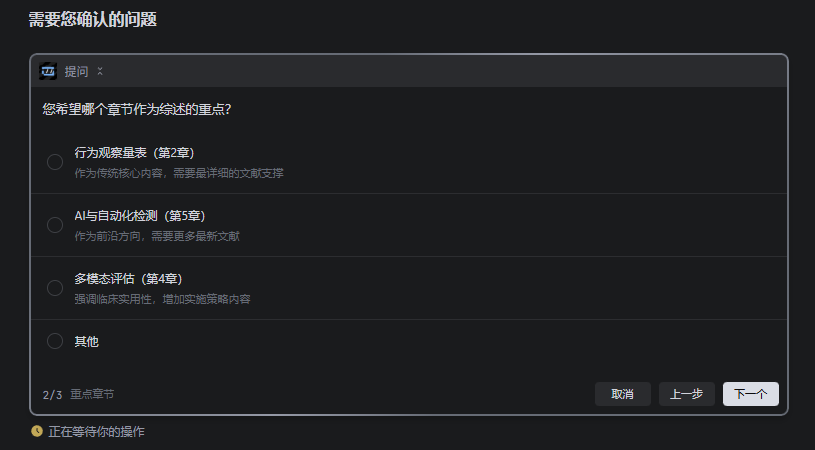
- 计划制定阶段:根据确认的大纲,制作详细的检索和撰写计划,保存为
plan.md - 逐章撰写阶段:按照计划,依次完成"确定章节主题 → 检索文献 → 撰写章节"的循环
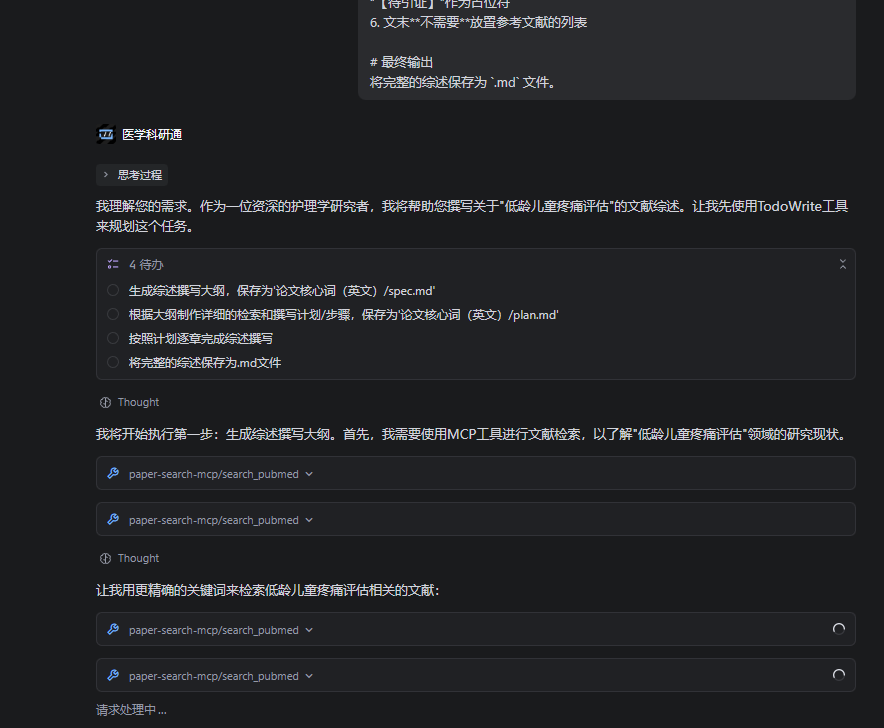
- 文件保存:将完整的综述保存为
draft.md文件
【操作提示】:在头脑风暴和大纲确认阶段,你可以随时提出修改意见,调整研究方向。这是确保综述质量的关键环节。
步骤 6:审阅和修改
Agent 完成后,打开生成的综述文件,进行人工审阅和修改。重点关注:
- 文献引用的准确性(逐一核对
[@doi:xxx]是否真实存在) - 逻辑结构的连贯性
- 专业术语的规范性
- 是否遗漏重要文献
【重要提醒】:AI Agent 是强大的辅助工具,但它仍然会存在幻觉,不能完全替代研究者的专业判断。最终的文献综述必须由研究者本人审阅、修改和负责。
进阶技巧
- 分步执行:对于复杂的综述任务,可以拆分为多个子任务,逐步完成
- 提供模板:如果你有特定的格式要求,可以提前准备好模板文件,让 Agent 按照模板填充内容
- 迭代优化:第一轮生成后,可以继续对话让 Agent 修改特定部分
- 文献管理:建议配合 Zotero、EndNote 等文献管理工具,建立个人文献库
- 配置自定义 Skills:在 Trae 中可以创建自定义 Skills,将常用的提示词模板、格式规范、期刊要求等封装为可复用的技能
从"快速了解领域"到"投稿级综述"
本教程演示的是一个快速入门的工作流,目的是帮助你在短时间内:
- 了解一个陌生领域的基本面貌
- 发现潜在的研究空白和选题方向
- 快速积累该领域的核心文献和关键概念
如果你希望完成一篇可以正式投稿的综述,还需要进行大量的后续工作:
| 后续工作 | 说明 | 所需工具/技能 |
|---|---|---|
| 论文结构精修 | 按照目标期刊的格式要求调整章节结构、字数限制、图表规范 | 期刊作者指南、LaTeX/Word 模板 |
| 撰文语气调整 | 确保学术语言的严谨性、客观性,避免 AI 生成的模板化表达 | 研究者本人的学术写作能力 |
| 参考文献列表生成 | 将 [@doi:xxx] 格式的引用转换为标准参考文献格式(APA、AMA、Vancouver 等) | Zotero + Better BibTeX、Pandoc |
| 文献质量评价 | 对纳入文献进行方法学质量评价(如 Cochrane 偏倚风险评估工具) | PRISMA 指南、ROBINS-I 工具 |
| 图表制作 | 绘制 PRISMA 流程图、数据提取表、森林图等 | R、Python、RevMan |
| 多轮迭代修改 | 与 Agent 反复沟通,逐段打磨语言、补充遗漏文献、调整论证逻辑 | 更精细的提示词设计、自定义 Skills |
【课程定位】:本教程是 AI 辅助撰写标准学术综述的前序课程。它起到抛砖引玉的作用,帮助你快速上手 AI 工具,体验从选题到生成初稿的完整流程。真正高质量的综述需要研究者投入大量时间,与 AI 深度协作,并配合专业的文献管理工具和方法学框架。
五、总结与展望
核心要点回顾
- 文献检索是科研的基石:它贯穿科研全生命周期,从选题到投稿,每一步都离不开高质量的文献检索
- 选题与检索的螺旋关系:临床经验 → 研究概念 → 文献检索 → 初步选题 → 再次检索论证 → 最终选题,这是一个迭代深化的过程
- AI 工具的演进逻辑:从孤立的大脑(LLM)→ 装上手脚(Tool Calling)→ 主动规划(Agent),理解这个脉络有助于我们更好地使用 AI
- 从网页 Agent 到本地 Agent:本地 Agent 通过工具调用机制(如 MCP、Skills)连接专业数据库,能够实现完整的文献综述自动化工作流
AI 在护理科研中的未来展望
随着 AI 技术的持续发展,我们可以期待:
- 更智能的文献筛选:AI 将能够更精准地理解研究者的需求,自动筛选高质量文献
- 跨语言检索能力:打破语言壁垒,同时检索中英文文献,提供更全面的研究视角
- 自动化质量评价:自动评估文献的方法学质量,辅助系统综述和 Meta 分析
- 个性化研究助手:基于研究者的专业背景和兴趣,提供定制化的文献推荐和研究建议
给护理研究者的建议
- 保持批判性思维:AI 是工具,不是决策者。最终的学术判断必须由研究者本人做出
- 持续学习:AI 技术迭代迅速,保持开放心态,积极尝试新工具、新方法
- 重视基础能力:无论 AI 多么强大,扎实的科研方法论和文献检索基础始终不可或缺
- 伦理意识:使用 AI 辅助研究时,注意数据隐私、学术诚信等伦理问题
【结语】:AI 不会取代护理研究者,但善用 AI 的护理研究者将在这个时代获得显著优势。希望本教程能够帮助你开启 AI 辅助科研之旅,让技术为你的学术探索插上翅膀。
Yield Nursing Logic, Optimized.
